· シン · gas-spreadsheet · 8 min read
GoogleスプレッドシートIMPORTXML関数:プログラム不要でWeb上のデータをピンポイント取得する基本技
プログラミングを1行も書かずに、Webサイトから商品価格や特定のテキストデータを自動取得できる「IMPORTXML関数」の基本と、抽出に不可欠な「xPath」の取得手順を丁寧に解説します。
こんにちは、e-Shikumi-Laboの シン です。 このブログでは、スプレッドシート&GAS、Chrome拡張機能をはじめとする自動化のTipsや、日々の現場での気づきを公開しています。
毎日の業務や情報収集の中で、特定のWebサイトから決まったデータ(商品の価格、為替レート、災害情報など)を「手作業で確認してコピペ」していませんか? 実は、複雑なプログラム(GASなど)を1行も書くことなく、数式ひとつでWeb上のデータを自動取得できる強力な関数がスプレッドシートには標準で備わっています。
それが、今回ご紹介する**「IMPORTXML(インポート・エックスエムエル)関数」**です。
自動化の「入力」プロセスの土台となるこの関数の使い方と、データの場所を指定する「xPath」の取得手順を分かりやすく解説します。
1. IMPORTXML関数の基本的な使い方
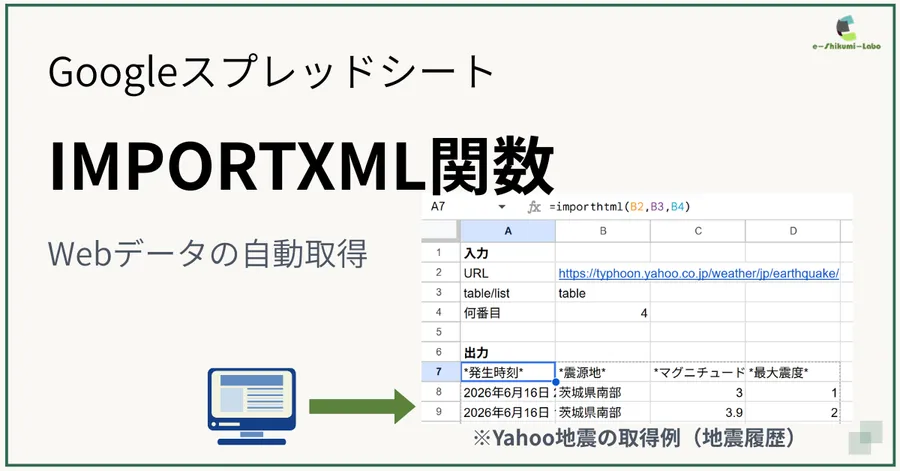
今回は、ヤフーの地震情報ページを例に、ページ内に表示されている最新の「地震発生時刻」をIMPORTXML関数で自動取得してみましょう。
- 対象ページ(Yahoo!天気・災害 地震情報)
https://typhoon.yahoo.co.jp/weather/jp/earthquake/
スプレッドシートを開き、データを展開したい空いているセルに以下の数式をそのまま入力してみてください。
=IMPORTXML("https://typhoon.yahoo.co.jp/weather/jp/earthquake/", "//*[@id=""eqinfdtl""]/table[1]/tbody/tr[1]/td[2]/small")この数式を入力すると、数秒の読み込み(Loading…)のあと、セルに指定したページの「直近の発生時刻(例:2026年6月14日 7時15分頃)」が自動でピタッと表示されます。
2. 肝となる「xPath(エックスパス)」とは?
IMPORTXML関数を動かすために必要なデータ(引数)は、次の2つだけです。
取得したいページのURL
取得したいデータの場所を示す「xPath」
URLはブラウザのアドレスバーからコピーすればOKですが、問題は「xPath」です。「なんだか難しそうな暗号に見える……」と身構えてしまうかもしれませんが、仕組みはとてもシンプル。xPathとは、Webページ内における「データの住所(ピンポイントな場所)」を表すものです。
この住所は、Google Chromeの「開発者ツール(デベロッパーツール)」を使えば、専門知識がなくても以下の5ステップで一瞬でコピーできます。
🛠️ Chromeを使ったxPathの取得手順
デベロッパーツールを開く 対象のWebページ(ヤフー地震情報)を開いた状態で、キーボードの
F12(MacはCmd + Option + I)を押すか、画面を右クリックして「検証」を選択し、開発者ツールを開きます。要素選択モード(矢印ボタン)を起動 デベロッパーツールの左上にある「矢印マークのボタン」をクリックします。
取得したいデータをクリック Webページ上で、取得したいデータ(今回の例なら「発生時刻」の文字部分)にマウスカーソルを合わせてクリックします。
対象のコードを右クリックしてコピー デベロッパーツール側で、クリックした箇所のHTMLコード(青くハイライトされた部分)が自動で選択されます。その部分を右クリックし、「Copy」 > 「Copy XPath」 を選択します。
テキストエディタ等に貼り付け これでクリップボードに住所データがコピーされます。※ただし、そのまま使うとエラーになる罠があるため、次の章で修正方法を解説します。
3. 実践で引っかかりやすいポイントと解決策
非常に便利な関数ですが、いざ自分で数式の中に貼り付けてみると、構文エラー(#ERROR!)で動かないという壁によくぶつかります。つまずきやすい注意点と、それを回避するコツをお伝えします。
💡 ダブルクォーテーションの「二重化」が必要
数式の中に直接xPathを書き込む場合、xPathの中に含まれているダブルクォーテーション(")をそのまま入れると、スプレッドシートが「ここで数式の文字列が終わりだ」と勘違いしてしまいます。 そのため、数式内に直接書くときは、xPath内の " を2つ重ねて "" に書き換える(エスケープする)必要があります。
そのまま貼り付けるとNG:
"//*[@id="js_scl_unitPrice"]"二重化するとOK:
"//*[@id=""js_scl_unitPrice""]"
💡 【おすすめ】URLとxPathは「別セル」に分ける
上記のエスケープ処理が面倒、あるいは数式が複雑で見づらくなると感じた場合は、URLとxPathをそれぞれ別のセルに入力し、関数からはそのセルを参照させる方法が一番スマートでおすすめです。
A1セル:
https://www.yodobashi.com/...(URL)B1セル:
//*[@id="js_scl_unitPrice"](xPathをそのまま貼り付け ※二重化は不要)C1セル(数式):
=IMPORTXML(A1, B1)
この方法であれば、エスケープの書き換え作業が一切不要になり、後から「取得先を変えたい」「別の場所を抜き出したい」となったときのメンテナンス(修正)が圧倒的に楽になります。まさにツールを自分でコントロールしやすくする「仕組み化」の工夫です 。
4. 便利だけど知っておくべき「自動化の限界」
IMPORTXML関数は手軽ですが、万能ではありません。あらかじめ知っておくべき「仕様上の限界」があります。
データ量が多いと「反応が遅く」なる ひとつのシートの中で、何十箇所、何百箇所もの大量のURLに対して一斉にIMPORTXML関数を実行すると、データの取得までに非常に時間がかかったり、途中で読み込みが止まってエラー(
#N/Aや Loading… のまま固まる)が発生しやすくなります。JavaScriptで動的に動いているページには通じない 近年、多くのWebサイトがJavaScript(ReactやVueなど)を使って、画面を開いた後にデータを遅れて読み込む仕組みを採用しています。
IMPORTXMLはページの「最初の生のHTML」しか読めないため、後から読み込まれるデータ(動的なコンテンツ)は取得できません。
5. まとめ
Googleスプレッドシートには、今回ご紹介した IMPORTXML 関数のように、プログラミングの深い知識がなくてもWeb上の情報をきれいに構造化して集められる機能が用意されています。
まずは身近なWebページをターゲットに、ぜひ一度試してみてください!