· シン · gas-spreadsheet · 8 min read
GoogleスプレッドシートIMPORTHTML関数:プログラム不要でWebデータを取得
プログラミング不要でWeb上のリストや表データをスプレッドシートに自動取得する「IMPORTHTML関数」の使い方とポイントを丁寧に解説します。

こんにちは、e-Shikumi-Laboの シン です。 このブログでは、スプレッドシート&GAS、Chrome拡張機能をはじめとする自動化のTipsや、日々の現場での気づきを公開しています。
今回はプログラム(GASなど)を1行も書くことなく、Web上のデータ(特に「リスト」や「表」)を丸ごと取得できる「IMPORTHTML関数」の使い方と、実践でのポイントを分かりやすく解説します。
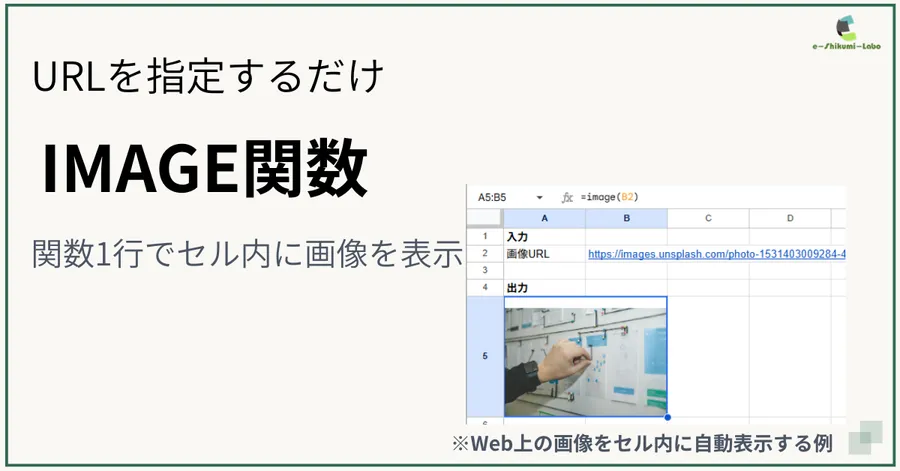
1. IMPORTHTML関数の基本的な使い方
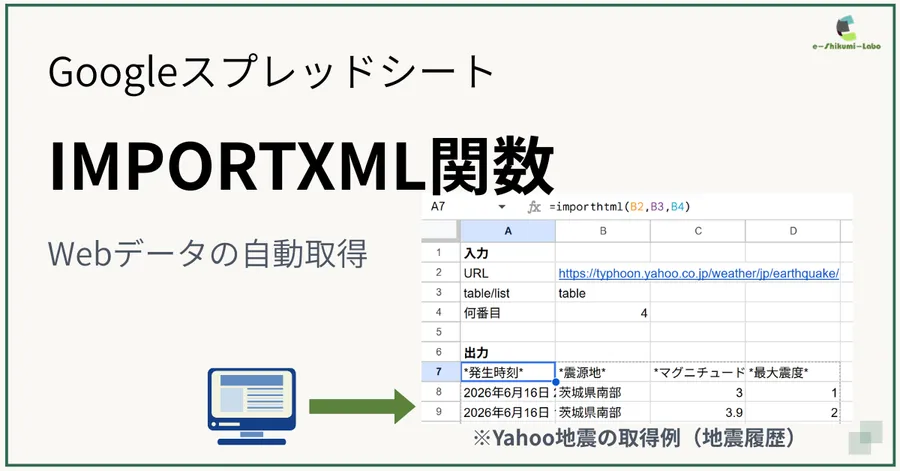
今回は、ヤフーの地震情報ページを例に、ページ内に表示されている最新の「地震の履歴」をIMPORTHTML関数で自動取得してみましょう。
- 対象ページ(Yahoo!天気・災害 地震情報)
https://typhoon.yahoo.co.jp/weather/jp/earthquake/
スプレッドシートを開き、データを展開したい空いているセルに以下の数式をそのまま入力してみてください。
=IMPORTHTML("https://typhoon.yahoo.co.jp/weather/jp/earthquake/", "table", 4)この数式を入力すると、指定したウェブページにある「地震の履歴」がスプレッドシート上にきれいに展開されます。
- 取得結果のイメージ (※指定したページのデザインや構造に合わせて、表データがそのままセルに流し込まれます)
2. 関数の引数(パラメータ)を解説
IMPORTHTML関数は、指定したWebページから「表(テーブル)」や「リスト」の部分をピンポイントで抽出してくる関数です。この関数を動かすために必要なデータ(引数)は、次の3つだけです。
URL
- データを取得したい対象ウェブページのURLを文字列として指定します。
データの種類( “table” または “list” )
取得したいデータのHTML構造が「表形式」か「リスト形式」かを選択します。
表形式 (
"table"): ウェブページ内の<table>タグで囲まれたデータを取得します。リスト形式 (
"list"): ウェブページ内の<ul>や<ol>タグで囲まれた箇条書きデータを取得します。
何番目のデータか(インデックス番号)
- 指定したページの中で、目的の表やリストが「上から数えて何番目に登場するか」を数字で指定します。
3. 実践で引っかかりやすい3つのポイント
シンプルで強力な関数ですが、実際に使ってみるとエラーが出てしまうことがあります。特につまずきやすいポイントを3つにまとめました。
💡 パラメータは必ずダブルクォーテーションで挟む
第一引数の「URL」と、第二引数の「データの種類(table / list)」は、必ず半角のダブルクォーテーション(")で囲んでください。これを忘れると構文エラー(#ERROR!)になります。
💡 数式を入力するセルの「周囲の空きスペース」に注意
IMPORTHTML関数は、入力したセルを起点として、右側や下方向へ自動的に複数のセルを使ってデータを展開します。もし、データが展開される予定の範囲に別の数字や文字、関数などが1箇所でも入力されていると、展開がブロックされて #REF! エラー(展開先のセルを上書きできません)が発生します。数式を入れるセルの周りは、あらかじめ十分に空けておきましょう。
💡【おすすめ】インデックス番号も「別セル」に切り出す
「何番目の表か分からないからといって、数式の中身を何度も書き換えるのはスマートではありません。URL、データの種類(table)、インデックス番号(数字)をそれぞれ別のセルに分けてしまいましょう。
- A1セル:URL
- B1セル:table or list
- C1セル:4(ここを1、2、3…と書き換えるだけ!)
- D1セル(数式):=IMPORTHTML(A1, B2, C1)
こうしておけば、数式を一切いじることなく、C1セルの数字をポチポチ変えるだけで目当ての表をパッと探し出せます。これもツールに振り回されず、自分でコントロールしやすくする『仕組み化思考』の工夫です。
4. 便利だけど知っておくべき「自動化の限界」
IMPORTHTML関数は手軽ですが、万能ではありません。あらかじめ知っておくべき「仕様上の限界」があります。ここを理解しておくことが、ツールに振り回されないための第一歩です。
データ量が多いと「反応が遅く」なる・固まる ひとつのシートの中で、何十箇所、何百箇所もの大量のURLに対して一斉に
IMPORTHTML関数を実行すると、データの取得までに非常に時間がかかったり、途中で読み込みが止まってエラー(#N/AやLoading...のまま固まる)が発生しやすくなります。特にIMPORTHTMLは「表やリストを丸ごと」セルに展開するため、関数を並べすぎるとスプレッドシート全体の動作が急激に重くなる原因になります。JavaScriptで動的に動いているページには通じない 近年、多くのWebサイト(ECサイトや動的な為替チャートなど)がJavaScriptを使って、画面を開いた後にデータを遅れて読み込む仕組みを採用しています。
IMPORTHTMLはページの「最初の生のHTML」しか読めないため、ブラウザ上では綺麗に見えている表であっても、後から読み込まれるデータ(動的なコンテンツ)は「そこに表が存在しない」と判定されて取得できません。
5. まとめ
このように、Googleスプレッドシートには複雑なプログラミング(GASなど)を一切行わなくても、Web上のデータを手軽に集められる便利な関数が標準で用意されています。
毎日の手作業でのコピペから脱却し、シンプルな「情報収集の仕組み」を作る第一歩として、ぜひあなたの業務でも試してみてください。