Googleスプレッドシートでは、プログラム(Google Apps Script)を使ってWebページのデータを取得する方法があります。それがUrlfetch関数を使用した方法です。
前回は、URLfetch関数の概要を紹介しました。

そこでも述べたとおり、URLfetch関数は文字列操作関数と組み合わせて使うことで力を発揮します。今回は、条件にあった文字列を抽出するための正規表現の使い方を紹介します。
正規表現とは
テキストの文字列から、条件にあった文字列を抽出するための「条件部」の書き方です。正規表現だけで本が出ているくらい奥が深いものです。

この正規表現と文字列検索関数・置換関数などを組み合わせると効率的に必要な処理が可能となります。
Webデータ取得に最低限使う正規表現
しっかり学べば効率よく必要な文字列を抽出できるようになる正規表現。しかし、学ぶ時間・試行錯誤する時間が必要です。今回は、正規表現を使って2つのキーワードに挟まれた文字列を抽出する方法「だけ」を紹介します。
それが、前回紹介したソースの中のこちらの2行です。
var myRegexp = /<title>([\s\S]*?)<\/title>/i; var tit = myRegexp.exec(response);
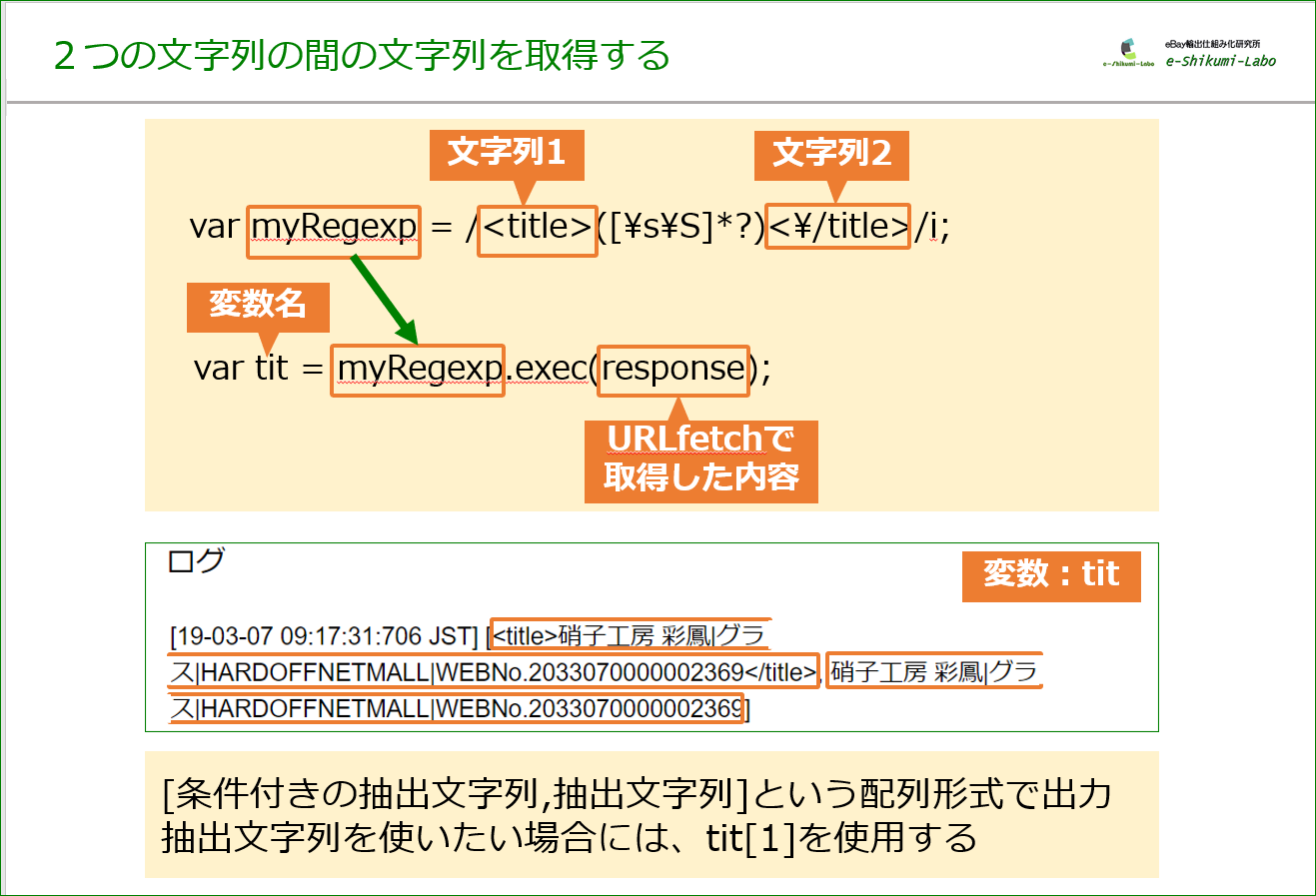
「文字列1<title>」と「文字列2</title>」で挟まれる文字列を抽出します。
抽出結果は、
[条件付きの抽出文字列,抽出文字列]
という配列形式で出力されます。抽出文字列を使いたい場合には、tit[1]を使用します。(GASの配列は「0」から始まるため、配列の2つ目の値は「1」と指定することになります。)
まとめ
今回は、URLfetch関数で抽出したHTMLから、正規表現を使って特定の文字列の間にある文字列を抽出する方法を紹介しました。正規表現の細かい説明は一切していませんが、このフォーマットを使えば、特定の文字列の抽出ができます。
まずは、このやり方を試してみて下さい。そして、こんなことができないか?こういう抽出ができないかなど出てきたら、改めて調べてみましょう。
