Googleスプレッドシートでは、プログラム(Google Apps Script)を使ってWebページのデータを取得(スクレイピング)する方法があります。それがUrlfetch関数を使用した方法です。
前回は、URLfetch関数の概要を紹介しました。

今回は、URLfetch関数を使って、実際のサイトの商品ページのWebデータを取得する方法を考え方を含めて紹介していきます。
Webデータ取得の基本的な考え方
特定のWebページから必要なデータを抽出する際の基本的な流れは次の通りです。
(1)URLfetch関数を使ってWebページのソース(HTML)を取得
(2)必要な文字列を囲んでいる固有のタグ・文字を検索して、正規表現を使って当該文字列を抽出
(3)文字列操作関数を使って(2)で抽出した文字列から不要な部分を削除
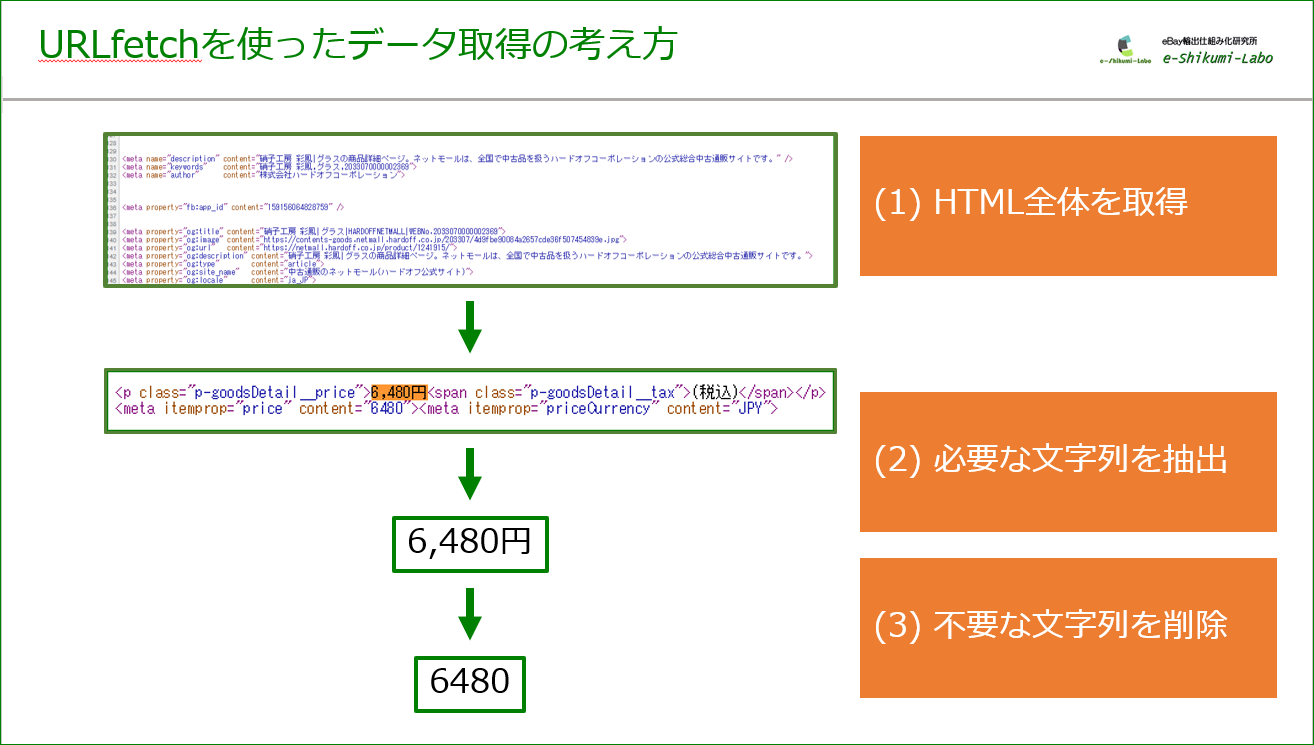
全体から必要な部分を抽出していくという流れになります。
実際のデータ取得作業の紹介
今回はネットモールの商品ページから、価格情報を取得する方法を紹介します。
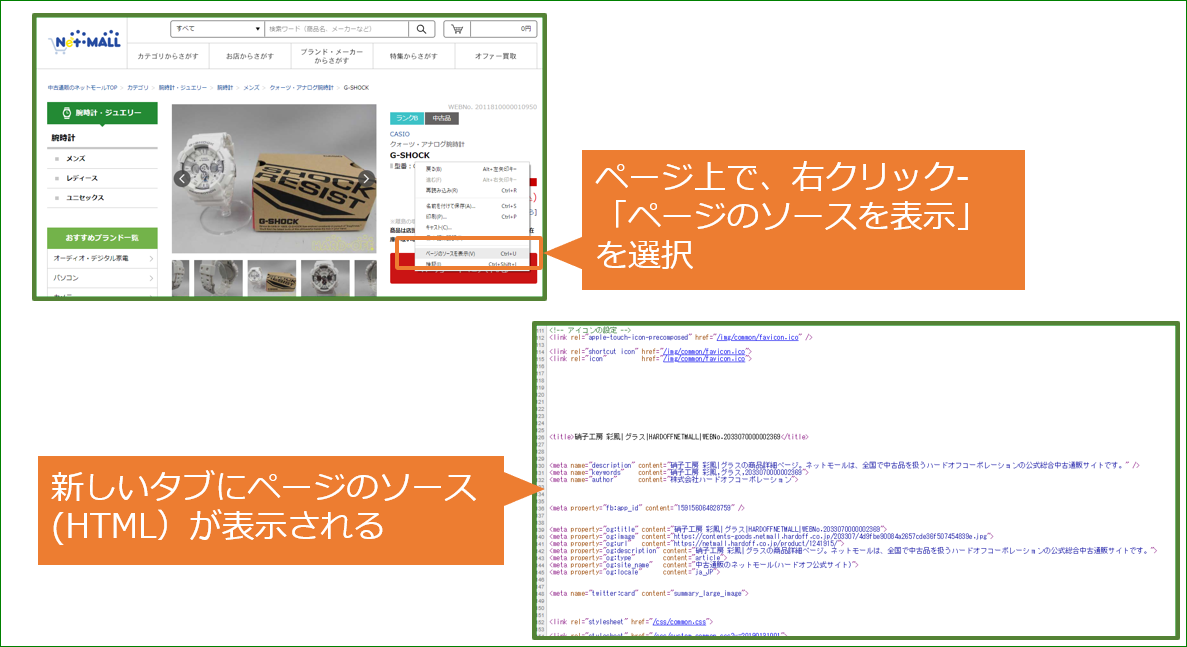
(1)URLfetch関数を使ってWebページのソース(HTML)を取得
URLfetch関数を使って、WebページのHTML全体を取得します。
//抽出するURL var url2="https://netmall.hardoff.co.jp/product/*****/" //実際のURLを入力 //URLfetch関数でHTMLを取得 var response = UrlFetchApp.fetch(url2); var response=response.getContentText();
(2)必要な文字列を囲んでいる固有のタグ・文字を検索して、正規表現を使って当該文字列を抽出
前回紹介した正規表現を使った文字列抽出の方法を使って、価格情報の前後にあるHTMLタグ(HTMLの制御文字)を調べた後、価格情報を含む文字列を抽出します。
今回の例の場合
前タグ(文字列1):<p class=”p-goodsDetail__price”>
後タグ(文字列2):<span class=”p-goodsDetail__tax”>
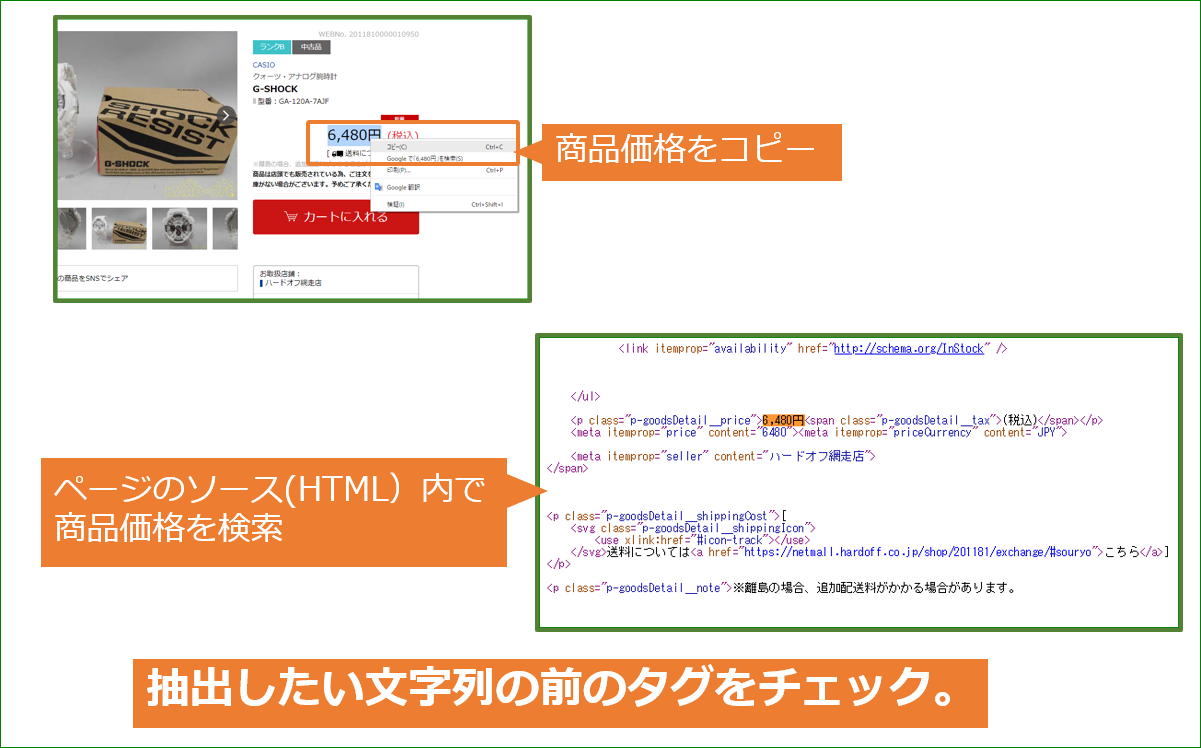
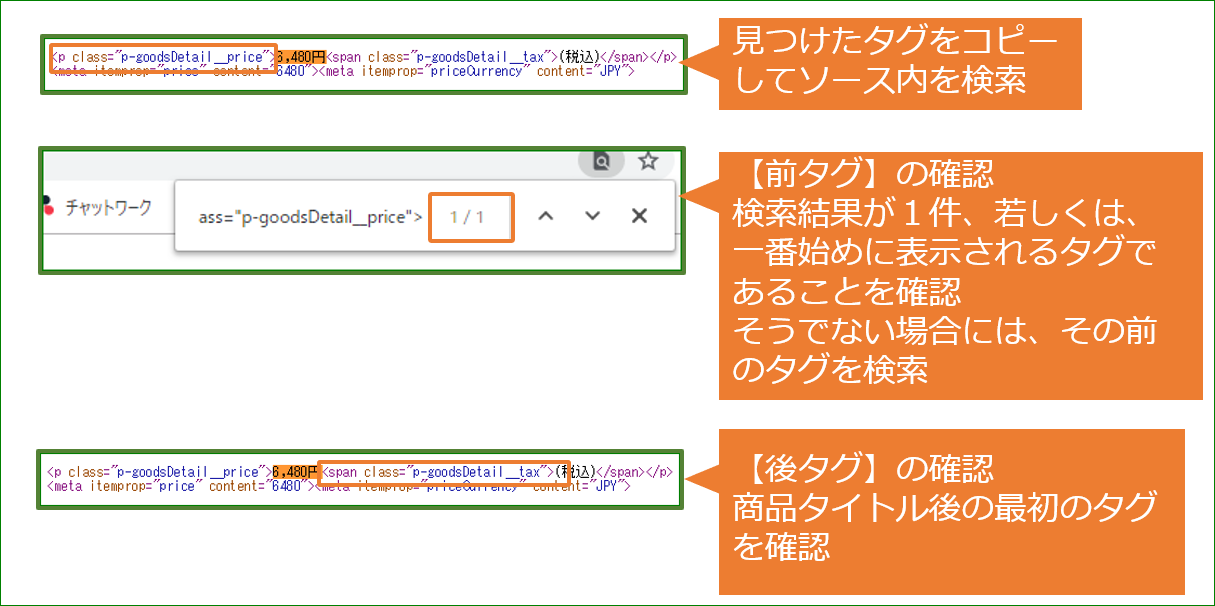
注)前タグ、後タグ内に「/」などの特殊文字がある場合には、その前に「\」を入力する必要があります。例</p> → <\/p>
//商品価格を取得 var myRegexp = /<p class="p-goodsDetail__price">([\s\S]*?)<span class="p-goodsDetail__tax">/i; var pri = myRegexp.exec(response);
(3)文字列操作関数を使って(2)で抽出した文字列から不要な部分を削除
今回は、Replace関数を使って、「,」と「円」を空欄に置換します。
var price=pri[1].replace(",","")
var price=price.replace("円","")
全体ソース
ソース全体は次の通りです。
function test() {
//抽出するURL
var url2="https://netmall.hardoff.co.jp/product/*****/"
//URLfetch関数でHTMLを取得
var response = UrlFetchApp.fetch(url2);
var response=response.getContentText();
//商品価格を取得
var myRegexp = /<p class="p-goodsDetail__price">([\s\S]*?)<span class="p-goodsDetail__tax">/i;
var pri = myRegexp.exec(response);
Logger.log("Price:"+pri[1])
var price=pri[1].replace(",","")
var price=price.replace("円","")
Logger.log("Price:"+price)
}
まとめ
今回は、URLfetch関数を使って、実際に実際のサイトの商品ページのWebデータを取得する方法を考え方を含めて紹介しました。基本は、全体を抽出して、そこから徐々に対象を絞って抽出するという流れになります。
次回は、商品検索結果のように複数の連続した複数の商品データを抽出する場合の考え方を紹介します。
