Googleスプレッドシートでは、プログラム(Google Apps Script)を使ってWebページのデータを取得(スクレイピング)する方法があります。それがUrlfetch関数を使用した方法です。
前回は、URLfetch関数を使って、実際に実際のサイトの商品ページのWebデータを取得する方法を考え方を含めて紹介しました。

今回は、URLfetch関数を使って、実際のサイトの商品検索結果ページのWebデータを取得する方法を考え方を含めて紹介していきます。
商品検索結果ページからのデータ取得の基本的な考え方
(おさらい)
特定のWebページから必要なデータを抽出する際の基本的な流れは次の通りです。
(1)URLfetch関数を使ってWebページのソース(HTML)を取得
(2)必要な文字列を囲んでいる固有のタグ・文字を検索して、正規表現を使って当該文字列を抽出
(3)文字列操作関数を使って(2)で抽出した文字列から不要な部分を削除
全体から必要な部分を抽出していくという流れになります。
商品検索結果ページから検索結果一覧を作成する方法も、基本的には前回と同じです。ただし、(1)と(2)の間に、取得したHTMLを検索結果ごとに区切るという操作が入ります。その後の操作は、区切った文字列に対して行います。
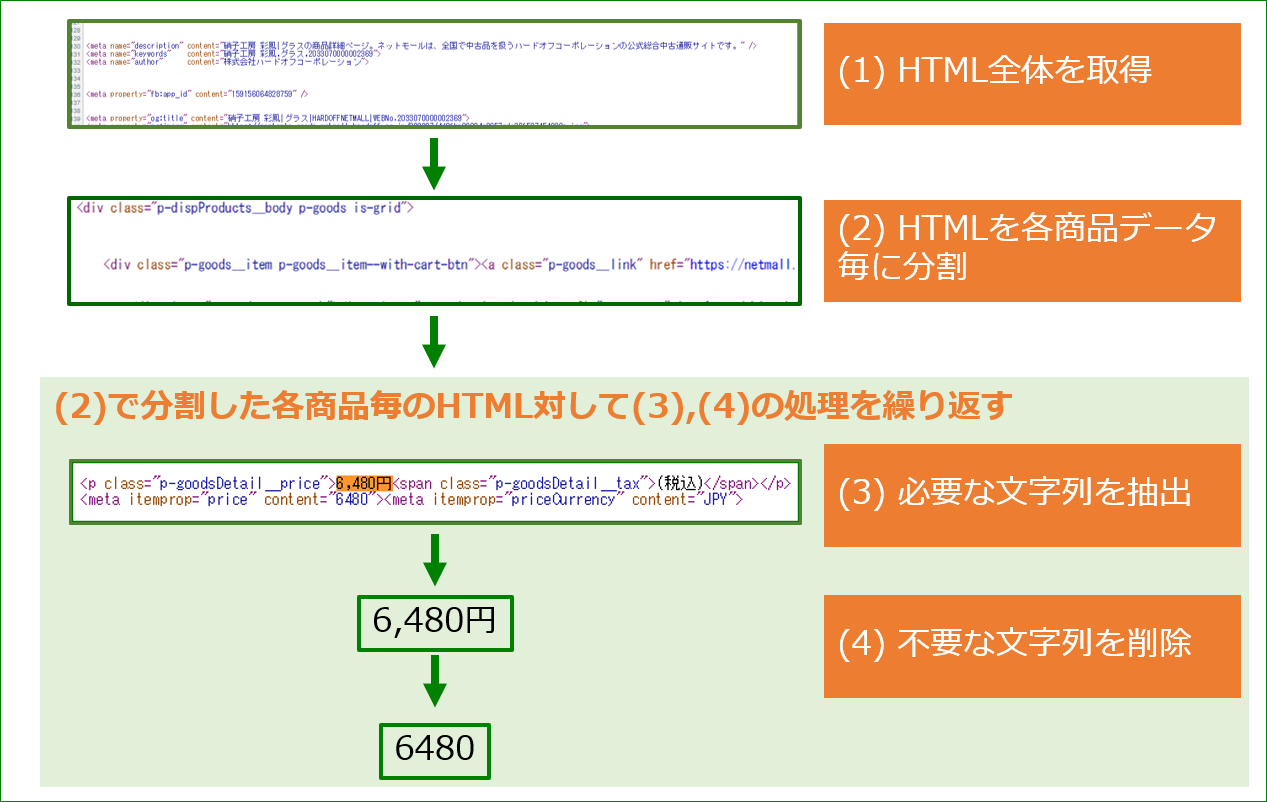
(1)URLfetch関数を使ってWebページのソース(HTML)を取得
(2)取得したHTMLを商品データ毎に区切る
(3)(2)で区切ったデータ内で必要な文字列を囲んでいる固有のタグ・文字を検索して、正規表現を使って当該文字列を抽出
(4)文字列操作関数を使って(3)で抽出した文字列から不要な部分を削除
(5)(3),(4)を繰り返す
実際のデータ取得作業の紹介
今回はネットモールの商品検索ページから、タイトル情報を取得する方法を紹介します。
(1)URLfetch関数を使ってWebページのソース(HTML)を取得
URLfetch関数を使って、WebページのHTML全体を取得します。
var url2="https://netmall.hardoff.co.jp/search/?exso=1&q=%E3%82%BB%E3%82%A4%E3%82%B3%E3%83%BC%E3%80%80%E8%85%95%E6%99%82%E8%A8%88" //URLfetch関数でHTMLを取得 var response = UrlFetchApp.fetch(url2); var response=response.getContentText();
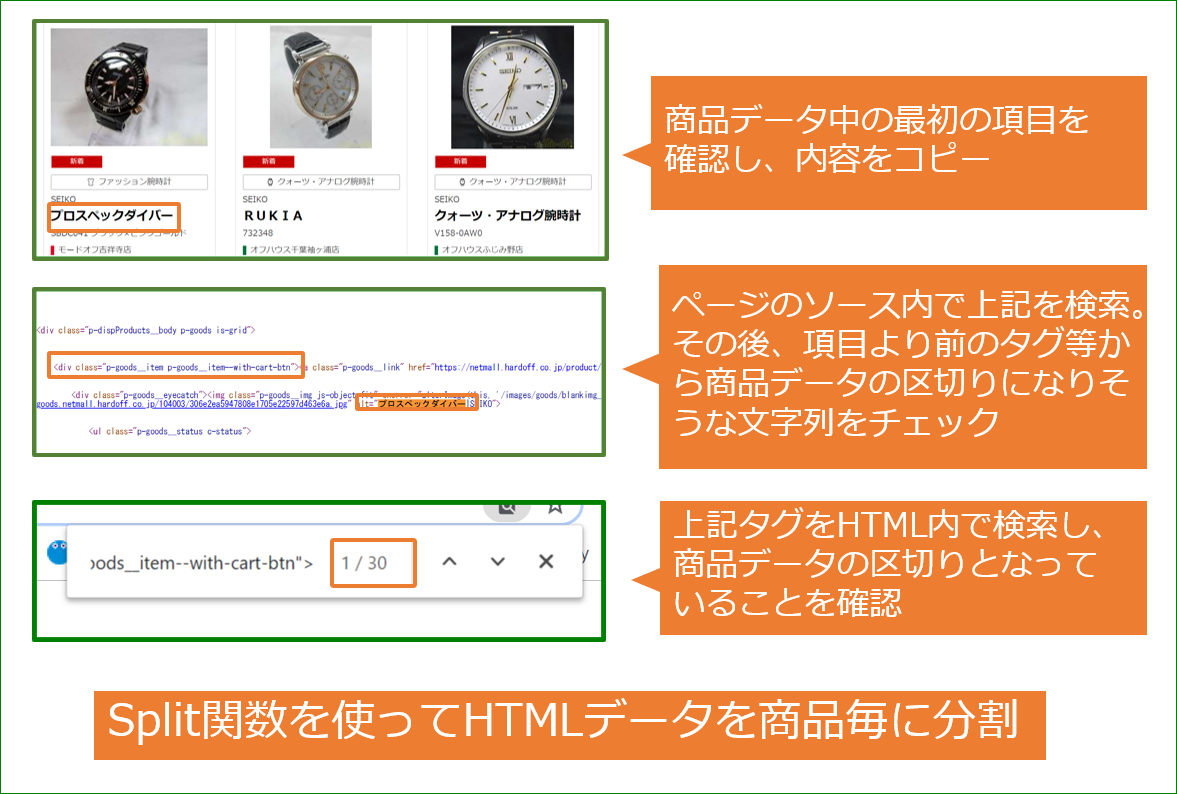
(2)取得したHTMLを商品データ毎に区切る
Split関数を使って(1)で取得した文字列を分割します。今回の例の場合、「
」という文字列で区切ります。なお、区切り文字内の「”」は特殊文字ですので、「\」を前に入れます。
//split
var dat=response.split("
<div class=\"p-goods__item p-goods__item--with-cart-btn\">")
Logger.log(dat.length)
(3)必要な文字列を囲んでいる固有のタグ・文字を検索して、正規表現を使って当該文字列を抽出
こちらで紹介した正規表現を使った文字列抽出の方法を使って、価格情報の前後にあるHTMLタグ(HTMLの制御文字)を調べた後、価格情報を含む文字列を抽出します。
今回の例の場合
前タグ(文字列1):
後タグ(文字列2):
注)前タグ、後タグ内に「/」などの特殊文字がある場合には、その前に「\」を入力する必要があります。例
→ <\/p>
//商品タイトルを取得
var myRegexp = /<span class="p-goods__nameClamp">([\s\S]*?)<\/span>/i;
var tit = myRegexp.exec(dat[i]);
Logger.log(tit[1])
}
(4)文字列操作関数を使って(2)で抽出した文字列から不要な部分を削除
今回は、タイトルをそのまま取得できるので不要です。
(5)(3),(4)を繰り返す
繰り返しを表す「for文」を使って(3),(4)を繰り返します。
ソース全体
ソース全体は次の通りです。
function test2() {
//商品検索ページデータ取得例
//抽出するURL
var url2="https://netmall.hardoff.co.jp/search/?exso=1&q=%E3%82%BB%E3%82%A4%E3%82%B3%E3%83%BC%E3%80%80%E8%85%95%E6%99%82%E8%A8%88"
//URLfetch関数でHTMLを取得
var response = UrlFetchApp.fetch(url2);
var response=response.getContentText();
//split
var dat=response.split("
<div class=\"p-goods__item p-goods__item--with-cart-btn\">")
Logger.log(dat.length)
for(var i=1;i<dat.length;i++){
//商品タイトルを取得
var myRegexp = /<span class="p-goods__nameClamp">([\s\S]*?)<\/span>/i;
var tit = myRegexp.exec(dat[i]);
Logger.log(tit[1])
}
}
まとめ
今回は、URLfetch関数を使って、実際に実際のサイトの商品検索ページのWebデータを取得する方法を考え方を含めて紹介しました。基本は、HTML全体を抽出して、それを商品ごとのデータに分割した後、分割したデータからデータを抽出するという考えになります。
いろいろなサイトで試してみて下さい。

